2021 年 7 月,由 SegmentFault 发起主办的系列技术沙龙 D-Day 强势回归,葡萄城技术布道师姚尧先生担任演讲嘉宾,就前端电子表格技术做了精彩的主题演讲。

姚尧的分享从前端电子表格领域性能、内存和可靠性三方面的技术实践出发,旨在通过有限的前端资源,帮助开发者用不到 100 行代码,在前端实现各类电子表格的功能。
以下是本次分享的精彩内容:
表格及其衍生技术的发展史
表格作为数据呈现的一种基本方式,在各类软件系统都发挥着重要的作用。在移动互联时代,即便再复杂的数据通过“表格”的整理,都可以清晰的呈现给用户,并支持用户从多个维度查看、筛选和修改。不论是应对文档、报告、凭证,还是票据,表格都能够附加存储更多的样式信息,尤其对离散式数据存储更加高效。
而在几乎所有的B端产品中,表格都作为一种交互式组件受到广泛欢迎。从技术层面来看,一款成熟的表格组件应具有高性能、低内存和可靠性高三个特点。
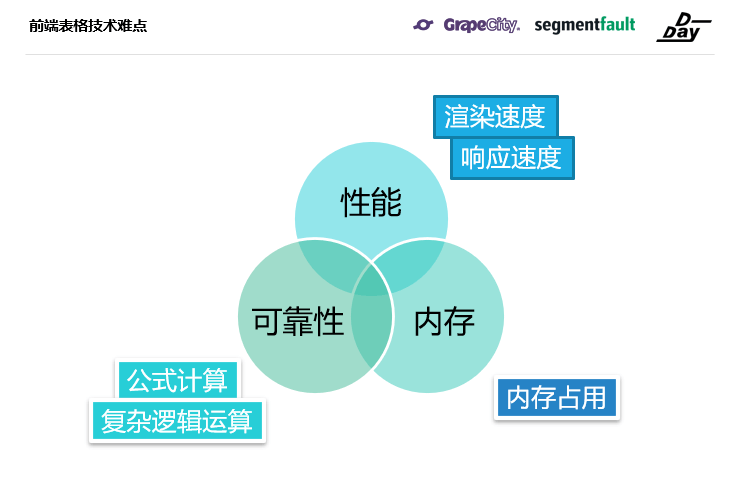
前端表格技术难点:性能
在企业应用中,数据是唯一的主干,作为数据载体的表格如果性能低下,便会被“吐槽”卡顿,UI界面“假死”,界面操作不流畅等。因此,对于经常用于展示大数据量的表格来说,性能显得至关重要。也就是说,任何基于表格开发的应用系统,必须满足以最低的资源消耗,实现高速渲染和刷新。
受限于浏览器渲染引擎的基础原理:当界面元素越多,浏览器的渲染时间会显著增长,内存消耗会越大,前端表格的性能主要体现以下三个方面:
在当页面从服务端下载了数据之后,表格是否能快速的呈现数据。
用户滚动、操作时,表格是否流畅。
当表格中有筛选、排序,以及大数据量的数据透视时是否能快速完成。
现代应用程序为了追求更好的用户体验,需要对UI界面反复优化,而频繁的修改界面UI元素,将引发多次浏览器重绘。在这个过程中,UI元素的创建及修改,会激活内部垃圾回收机制,影响数据处理效率。除此之外,前端开发环境的多样化、各类高DPI设备、手机、平板、4K显示屏、企业大屏等,也将于无形中加重企业应用系统的处理负担。
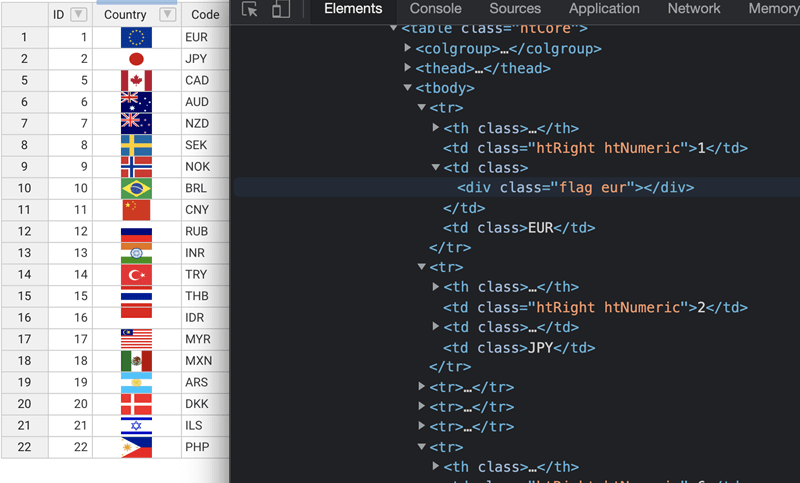
在canvas出现之前,表格在前端的渲染只能通过构建复杂的DOM来实现,为了解决这个问题,前端框架React和Vue3均采用了虚拟DOM的方式,而经过研究,葡萄城采用了一种更为先进的方式——HTML5 Canvas绘制。
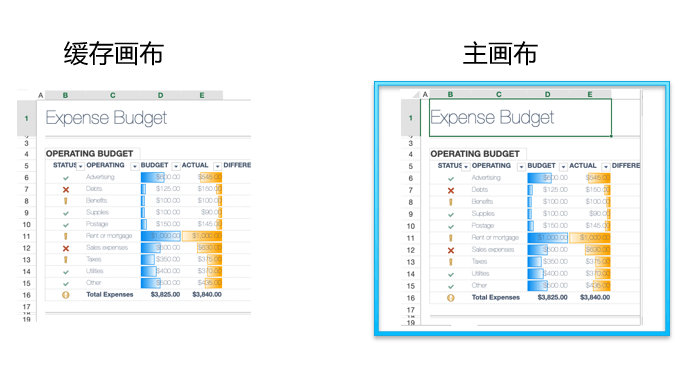 (葡萄城双缓存画布技术)
(葡萄城双缓存画布技术)
葡萄城双缓存画布的技术特点:
类似油画的分层绘制:绘制引擎基于油画的绘制原理,分为主体图层和装饰图层,主体图层渲染持久的、不易改变的元素,例如背景,单元格,表格线等。装饰图层则渲染常变性元素,如选择框、拖拽框、悬浮效果等。
使用缓存画布:当发生动态绘制,如表格滚动时,SpreadJS会将主画布清空,从缓存画布中根据行为上下文进行画布偏移,将偏移后的图层直接绘制在主画布上,再在主画布上绘制剩余部分,使整个表格的滚动过程更加流畅。
前端表格技术难点:内存
做开发的都知道,想让系统变快有个最简单的办法就是加内存。对于程序可以做大量的缓存来加速,但是在浏览器环境,一个网页可使用的内存是有限的。
虽然没有明文规定,但在业界的共同认知里,浏览器会对单一线程进行内存限制,例如64位的chrome,每个tab页的内存消耗不允许超过4G,在手持设备上,这个限制则更为明显,例如iPhone 6s为1G,而iPhone 7为2G。
这个限制,在单页面应用不成熟的十几年前,不会成为问题。因为,那时大家所关注的,还是如何提升后端的处理性能,前端只是一种静态的网页表达方式。
随着前端工程化的高速发展,各种前端工程脚手架日渐成熟,WebComponent标准被提上日程,企业开始由C/S向B/S应用转型。这就要求前端开发者,需要面对单线程处理复杂业务数据的挑战。这里的复杂,不仅仅是数据量大,更是数据状态的处理。
因此,产品从最开始设计以及运行时都需要考虑内存的使用情况,尽可能的降低内存占用,防止网页崩溃。
为了更高效的解决数据的前后端交互,快速响应数据变更及数据回滚,葡萄城改变了表格数据的存储方式,由常规数组改为稀疏矩阵。
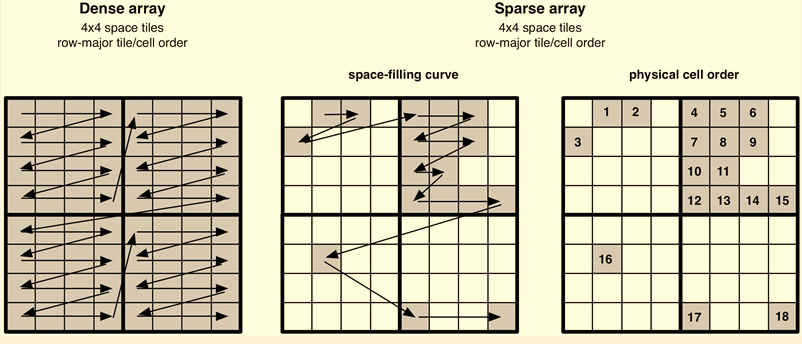
相较于传统的链式存储或是数组存储,稀疏矩阵存储构建了基于行索引为Key的数据字典,在松散布局的表格数据中,稀疏矩阵只会对非空数据进行存储,而不需要对空数据开辟额外的内存空间。使用这种特殊的存储策略,使得数据片段化变得容易,可以随时框取整个数据层中的一片数据,进行序列化或反序列化。
借用这样的特性,我们可以随时替换或恢复整个存储结构中的任何一个级别的节点,以改变引用的方式高效解决了表格数据回滚和恢复,而这一点也是电子表格支持在线协同的一个基础。
另外,使用稀疏矩阵带来了另一个优势,在数据检索遍历时,无需判空,只要对有效数据校验即可。
前端表格技术难点:可靠性
这里可靠性并不是只软件的稳定性,而是说对于有计算能力的表格,在做复杂计算的时候是否能高效的提供可靠的结果。
比如在类Excel的电子表格中提供了设置Excel公式的能力,那这种Excel公式如何正确的解析并计算也是衡量表格能力的一个重要指标。表面看似简单的Excel公式,却具备高阶编程语言的一切特性,如语法分析、解析、运算、执行等。
当用户设置一个公式到表格中,计算引擎会将其解析为一个中缀表达式,如公式“SUM(A1:B1, 3/E1, C1) + 2*(D1 - 1)”,当通过计算引擎的解析后,会在内存中以树型结构进行存储,这个树型结构被我们称为表达式树。表达式树的生成,是后续构建计算依赖链的关键。
当一个公式被解析为表达式树后,计算引擎将根据运算上下文为其构建运算依赖链。运算依赖链的目的是为了按需计算,当表格内容发生变化时,只有被影响的表达式树会进行运算,而运算的依据就是依赖链。

如上图所示,这是葡萄城表格组件的计算引擎在构建计算依赖链时的一个简单的流程图,表达式树从计算存储模型中找到对应的根节点以及根节点标识,随后遍历整个表达式树,找出其他依赖标识,构建依赖关系。
当整个依赖链中的任意节点发生变化时,沿着这条依赖链,计算引擎会查找依赖节点并进行重算,这个过程中,没有在依赖链中的节点是不会发生重算计算的,也就是我们所说的脏值运算。
也正是利用这样的机制,葡萄城的表格组件才得以大大提升了整个表格的运算速度,给用户更好的使用体验和更加精准的运算结果。
计算公式可靠性的实际案例:IRR

IRR是一种投资的评估方法,也就是找出资产潜在的回报率,其原理是利用内部回报率折现,投资的净现值恰好等于零,Excel、Google Sheets都有这个公式,一些专业的财务软件也提供类似功能。
内部收益率(IRR)衡量投资的收益率。 “内部”一词是指内部利率不包括外部因素,如通货膨胀,资本成本或各种金融风险。在最开始计算五年的回报率时,我们按照标准的牛顿算法写出了迭代计算逻辑,很长时间也没有收到任何反馈,突然有段时间几家客户同时反馈说IRR结果和Excel不一致,于是我们调整了算法,问题得以解决。
但是,没多久客户反馈又出现了不一致问题,这个时候就犯难了,Excel没有提供这个公式的具体算法,我们有看了Google Sheets和一些专业的财务软件,发现在一些极端case下,大家都不一样,有些甚至给出了N/A也就是无法计算的结果。
通过NPV淨現值法(Net present value)反推,可以证明我们的结果是对的,而造成这个问题的原因是在Excel或者Google Sheets中不同的guess会导致结果的抖动,由于目前没有一个标准说明哪个值更合理,我们暂时采用了和Excel一致的计算结果,但对于这部分的研究一直没有停滞。
前端表格技术难点:其他
除了绘制引擎、存储策略和计算引擎外,葡萄城的前端表格技术还攻克了许多技术难点,例如触摸支持、富文本支持、前端Excel导入导出、JSON存储等,而这些技术点,承载了葡萄城数年来在表格控件的开发技术和长期服务于开发者的经验积累。
目前,葡萄城的表格组件已广泛应用于各行业的信息化系统开发中,满足表格文档协同编辑、 数据填报、 类 Excel 报表设计等业务场景,帮助企业搭建出功能和布局均高度类似于 Excel的软件系统,加速企业信息系统的交付,完美匹配在线办公场景和前端表格系统开发需求。
如果您需要进一步了解葡萄城前端表格技术,欢迎前往葡萄城产品官网,免费下载体验。











