在上节中,我们为大家介绍了Pod的基础内容,Kubernetes如何站在上帝视角上处理容器和容器之间的关系。但仅仅有Pod却还不够,对于大部分用户而言如何调度和管理自己的应用才是真正核心的问题,而对这一内容的解决方案才是Kubernetes最终极大杀器。
让我们从一个例子出发,假设现在的用户需求是:
以3机负载均衡的形式部署一个私有云客户的活字格应用,应该如何实现呢?

Docker的“古典”做法
在活字格公有云版开发组之前开发的版本中,实现方法大概是这样:使用三个不同的物理机,先把用户的应用run成容器,然后安装在在这三个物理机上,在三台服务器之外再买一个负载均衡服务,最后通过域名解析配置,将流量分别导向三个不同的服务机。
有没有感觉So easy!!!听起来似乎也挺简单的。
耳朵会了,脑袋也跟上了吗?在现实中,我们会遇到很多烧脑的问题,比如:如果我们只有两台服务器呢?如果有一台服务器中的container挂了呢?如果两台服务器CPU跑满了呢?
这些调度方面的内容看起来很简单,但是实现起来却需要长时间的编码和调试。而且一通输出之后,最终做出来也可能只是个Docker Swarm而已。

Kubernetes里的容器编排
现在我们把上述需求看做是我们最终的目标,来看kubernetes是如何一步一步进行容器编排从而解决了这个问题。相信大家看完这部分内容之后,以上问题便会迎刃而解。
Kubernetes所做的容器编排核心内容其实是Pod编排,如何让这些Pod配合起来协同工作,则是编排的核心。在上一节中我们一起了解了kubernetes所做的是将各种关系进行了抽象,这些关系本质其实是Pod之间的关系。kubernetes将Pod的关系抽象成了以下几种,并且为这些关系定义了相对的控制器便于进行编排管理:
- 无状态Pod副本之间的协同关系——Deployment
- 有状态Pod副本之间的拓扑关系——StatefulSet
- 容器化守护进程——DaemonSet
- 离线业务——Job和CronJob
这些概念看起来可能让你有些不知所云,其实这些内容只是不同控制器对Pod不同的管理方式而已。
限于篇幅和对这部分内容的理解深度,这里我们将只分享活字格公有云版开发组中最多使用到kubernetes最常用的一种控制器——Deployment。
Deployment控制器功能介绍
我们先解释什么是控制器:控制器是kubernetes中管理待编排对象的程序,我们把一个对象管理另一个对象的模式称为控制器模式。
kubernetes中的所有待编排对象都是通过控制器模式管理的。
其核心就是一个死循环,在循环中不停地判断当前编排对象的状态,如果不满足预期状态就更新它,如下的伪代码就是描述一个控制器的工作原理:

Deployment控制器的功能是:维护多个相同的无状态Pod副本以规定的数量运行,并且支持水平扩展以及滚动更新。
有了这个控制,为了实现我们的最终需求——负载均衡中的活字格服务,这个Pod就可以通过Deployment管理。我们可以通过Deployment让我们的Pod在kubernetes集群中始终以3个副本的形式存在。
只需要用Deployment来编排我们定义的Pod,并且要求副本数量是3,Deployment控制循环中就会不停地判断我们的Pod的副本数量是否是3,如果不是,就会触发水平扩展功能进行调整,最终达到满足期望状态(副本数==3)。
Deployment工作原理演示
介绍了这么多,我们从实例出发为大家演示Deployment是如何工作的。
由于活字格的镜像配置过于复杂,因此这里我们通过一个Nginx的多副本配置来感受一下Deployment控制器的控制结果。
我们可以通过以下yaml定义一个维护了3个nginx副本的deployment:
其实Kubernetes在最初的版本中只有ReplicaSet这种控制器模式,控制的是多副本Pod编排逻辑,后来出现了滚动更新逻辑,为了解决滚动更新的需求,在ReplicaSet基础上扩展出了Deployment。
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-deployment-nginx
spec:
selector:
matchLabels:
app: sample-deployment-nginx
replicas: 3
template:
metadata:
labels:
app: sample-deployment-nginx
spec:
containers:
- name: sample-nginx
image: nginx:1.9.1
ports:
- containerPort: 80
这里出现了三个特殊字段:
selector:选择器,类似于js中的选择器,其功能就是选择指定的pod运行,这个实例中我们指定所有app==sample-deployment-nginx的pod才会被这个Deployment所部署
replicas:指明这个Deployment维护的副本个数
template:控制器中提供了template这个语法,可以让我们直接在控制器的yaml中直接编写所需要编排的Pod信息
编写完这个sample-deployment-nginx.yaml后,执行一下:
kubectl apply -f sample-deployment-nginx.yaml
这个三副本的控制器就被成功运行了,使用该指令查看运行结果:
kubectl get pods -l app=sample-deployment-nginx
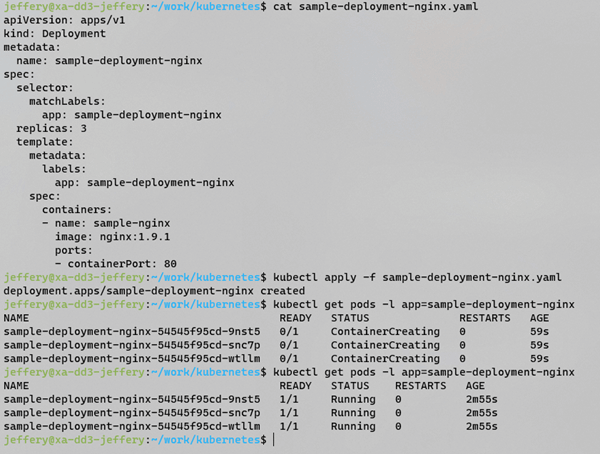
可以看到3副本Pod已经成功在kubernetes中运行了
如果这时我们执行以下命令删除podname==sample-deployment-nginx-54545f95cd-wtllm的副本
kubectl delete pod sample-deployment-nginx-54545f95cd-wtllm
可以自动生成一个新的pod来维持replicas==3:
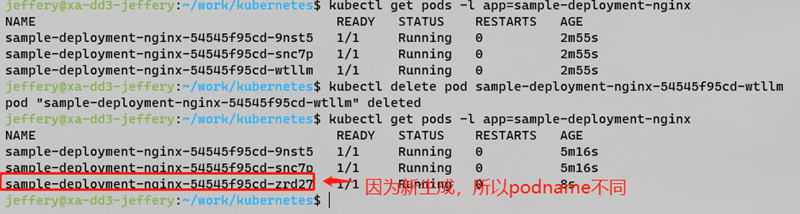
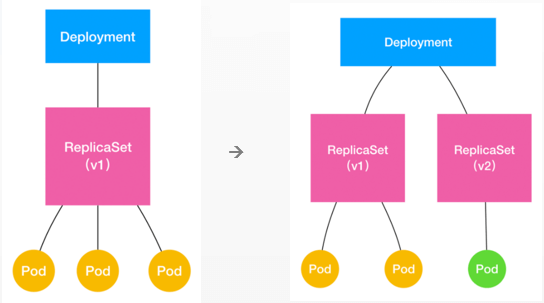
通过上述实例,我们可以看到Deployment控制器对副本数量的控制结果,其实是ReplicaSet控制器在控制副本的数量。Deployment是ReplicaSet控制器的控制器,这种多层之间相互控制的模式在kubernetes也十分常见,其之间的关系如下图所示:

至此,一个deployment管理pod的所有功能都已经展示完成了,可以看到kubernetes中控制器管理之间的精巧关系:多个控制器协同工作,既保证精准控制,也能拆分进程阻塞从而提升性能。
其他控制器的介绍
当你理解了deployment控制器,就很容易理解其他控制器的工作原理。
在这里我们简单做个说明,为大家介绍其他控制器的控制逻辑:
- StatefulSet:控制满足有拓扑状态或者持久化存储的Pod,拓扑状态的意思就是Pod之间存在明确的先后生成关系,持久化存储就是当副本被删除或者修改了,其内部保存的数据还会存在
- DaemonSet:守护进程控制器,是一个Node(服务器节点)仅能存在一个的Pod,比如系统的日志采集器等就应该用这种方式调度
- Job与CronJob:Job就是任务调度,一个Pod在调度完成后就结束了不会再有新的任务产生,Job用于维护一个任务Pod运行中的各种状态正常,异常状态重启等。对应的CronJob就是定时任务,使用过Quartz的同学一定不陌生
总结
综上,kubernetes中就是通过上述的各种控制器维护所有Pod的编排工作的,并且其还提供了完善的API可以让用户自行定义满足自己需求的各种Pod编排控制器。但是对于deployment本文只是简单的展示了一些常用的功能点,其内部还有滚动更新的最大资源、金丝雀发布和灰度发布等各种功能需要继续细致的学习。
本章中以活字格公有云为例,为大家介绍了k8s容器编排部分的实现。在下节中我们将继续为大家分享,为了实现这个终极需求的另一部分——如何实现 “人与狗的交往过程”。









.K1AHo.png)

